Arrcus VDR: The Virtualized Distributed Routing System
November 5, 2020 | Nalinaksh Pai
Supporting up to 768Tbps of routing performance, the Virtualized Distributed Router (VDR), a distributed routing system built using standalone ODM/OEM networking and server units, provides supply base diversification while offering unprecedented port density and scale, well beyond the limits of a traditional chassis-based solution.
In this blog, we provide a technical overview of the VDR.
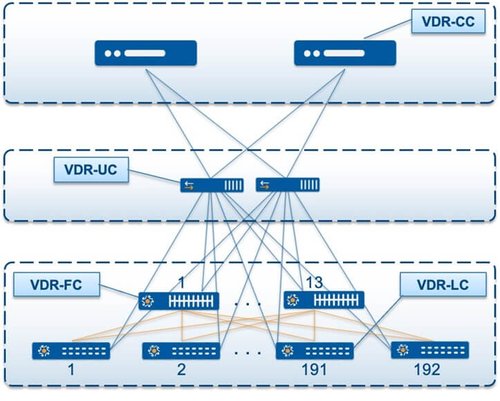
Figure 1: VDR Cluster
A typical VDR cluster is made up of the following types of nodes:
The VDR is powered by ArcOS (Arrcus Operating System), a modern-day microservices-based networking operating system solution, that has been proven across a variety of scaled production deployments and environments. ArcOS runs in a distributed manner across the VDR cluster, discovering and provisioning the various nodes in a Zero Touch manner. Once installed the user can configure and operate the VDR through a ‘single pane’ of management and control, similar to what’s expected in a traditional chassis-based routing system.
The different nodes in the VDR cluster run different functions:
The VDR-CC runs the ArcOS management, control, and orchestration planes.
The ArcOS management plane manages the router configuration and provides a rich set of services such as CLI, NETCONF, RESTCONF, SNMP, and Telemetry.
The ArcOS control plane is composed of various protocols, features, and infrastructure that carry out core functions such as routing, neighbor discovery, interface management and so on. The VDR software automatically sets up the packet punt-path between the VDR-CC and the VDR-LCs so that these processes can send and receive packets over front panel interfaces on the remote VDR-LCs as if they were locally present on the VDR-CC.
Finally, the VDR orchestration plane manages the orchestration of various software components and functions across the cluster. The VDR orchestrator leverages the microservices-based architecture of ArcOS to spawn the appropriate set of containers on each node in the cluster.
The distributed nature of the VDR offers a scalable, build-as-you-grow model that cannot be matched by a traditional chassis due to its physical constraints. However, this distributed architecture also brings with it a new set of challenges and opportunities.
Scale
A fully scaled VDR system can scale up to hundreds of LCs and thousands of interfaces and peers. Such a system needs a reliable control plane that can step up and operate at that scale. The core router software and infrastructure in ArcOS have been designed keeping such scale in mind. They have the ability to take advantage of multi-core CPUs and 64-bit addressing to scale with respect to the number of routes, peers, and interfaces. This was the driving factor in the decision to offload the control plane to powerful commodity x86 servers, where we are no longer restricted by the number of CPUs or memory on a traditional router-processor card.
The VDR software is designed to run across multiple servers if and when scale or high availability demands it. It is also capable of taking advantage of local compute available on the LCs and FCs to offload specific functions that can benefit from being closer to the data path – for e.g., LACP, BFD, etc.
The VDR orchestrator is built on top of widely used Kubernetes, which has proven its container orchestration credentials in the largest of datacenters. Careful thought has gone into the design to ensure that interaction with Kubernetes is kept at an appropriate level so that response to time-sensitive events is not dependent upon it.
High Availability
We realize that VDR, like any distributed system, is susceptible to individual components failing at different times for different reasons. The key requirement is that the system must be resilient and highly available from both a hardware and a software point of view and not fail as a whole when an individual component fails.
Hardware redundancy
A fully redundant fabric can be built by incorporating multiple VDR-FCs. Failures in the fabric are handled by protocols running inside the networking chips on the VDR-LCs and VDR-FCs.
The underlay network consists of multiple VDR-UCs to protect against VDR-UC and/or link failures. Each VDR-LC, VDR-FC, and VDR-CC can connect up to two VDR-UCs for link redundancy.
The VDR peers can connect to multiple VDR-LCs and use link bundling or layer 3 ECMP to utilize multiple paths and protect against link and node failures.
Finally, the user can provision a pair of VDR-CCs to protect against a VDR-CC failure. In fact, the VDR architecture allows more than two VDR-CCs to be connected for scaling the workloads and redundancy when the need dictates it.
Software resiliency and redundancy
Processes in ArcOS are capable of restarting in a graceful fashion without disrupting packet forwarding. This is done by checkpointing necessary state, which upon a restart helps to gracefully reconcile the newly learnt state with the existing state. The routing protocols support graceful restart mechanisms to instruct peers to keep forwarding traffic while they restart and re-converge gracefully. To protect against VDR-CC failures, the state is checkpointed to a standby VDR-CC to keep it ‘warm’ enough to resume operations in a prompt fashion, in case the active VDR-CC fails.
The VDR software has been purposefully designed to handle the failure scenarios around control plane connectivity to the distributed data path units. Right from installation through operation, the VDR software continuously monitors the cluster topology and matches it to an intended state. It flags incorrect, or failing, or failed connections and nodes in a prompt fashion and takes corrective action to use redundant paths.
Finally, failed nodes can be replaced without taking down the entire cluster for maintenance. For e.g., VDR-LCs and VDR-FCs can be swapped with new hardware in a fashion where the existing configuration pertaining to the replaced nodes is seamlessly applied to the new ones after they have been brought up.
Incremental Growth
Unlike a traditional chassis the VDR provides truly incremental growth. The software does not make any assumptions about the size of the ‘cluster’ and provides an elastic build-as-you-grow model. The administrator can start off with a small cluster of, say, two FCs and two LCs, and seamlessly add more LCs and FCs when needed without having to tear down the cluster to add new ones. In other words, adding a new VDR-LC to an existing VDR cluster is no different than inserting a new LC into a traditional chassis in terms of operator experience.
Ease of Operations and Troubleshooting
The VDR leverages ArcOS’s streaming telemetry capabilities to provide the operator deep insight and visibility into the system’s health. The various VDR components stream out routing, link statistics, and other vital metrics to the VDR-CC, where this data is monitored to compute a system-wide health report, that can be accessed through CLI and other management interfaces to get a high-level insight into the health of the VDR system. The operator can then ‘dive’ into a particular functional area on a particular node and inspect statistics and metrics at a lower level. These statistics and metrics are not only accessible through CLI but can also be streamed out via telemetry to ArcIQ where the user can take advantage of its visual capabilities and analytics engine to get a deeper insight into the operational health of the VDR system.
The goal of this blog was to provide you an overview of VDR and some of the fundamental design principles that make it a truly innovative routing system. If you are interested in learning more, please request a demo or contact us at www.arrcus.com.
Categories
5G
ACE
AI
ArcEdge
ArcIQ
ARCOS
ARRCUS
CLOUD
datacenters
edge
FlexAlgo
hybrid
Internet
INVESTING
IPV4
IPV6
MCN
ML
multicloud
Multicloud
MUP
NETWORKING
NETWORKING INDUSTRY
Routing
SRV6
uSID
2077 Gateway Place Suite 400 San Jose, CA, 95110
Site by